Author here, I actually think so. The rendering of the virtual DOM as well as hooks are fairly interesting mathematical constructs. A pattern I use a lot in web applications is the state reducer, which is really a fold over events and state. Seeing the functional nature of it (and reactive programming in general) can make for quite composable react code, while it is easy to make either a verbose mess of propdrilling or do a lot of tricky context mixing.
I'd love to see some examples of your diagrams. Are they all hand-written or do you use online tools for them? I do quite a bit of graph diagramming but not for detailed planning of implementation. Best example I've seen along those lines are the xState tools for state charts (https://stately.ai/viz).
This looks very mundane but I do think about it very mathematically as well: user interaction with a search engine. The "encode" arrow for example is very much about NLP and tokenizing, which is a functor from the "category" of natural language to the functor of "lucene tokens" which then has a functor to "lucene queries". This is of course the very mundane typing of functions as:
function parseQuery(query: NaturalLanguageString): LuceneQuery
nothing spectacular, but the abstract approach means I know I can cache/batch/precompute/distribute/pipeline/modularize it.
Similar mathematical concepts apply to all the other arrows, even if some are a bit wild (how does a search result influence a person's ideas?) But it means I can try to model the "wildness", and create say a probabilistic model to exercise and understand how my search engine actually performs (see for example click models and probabilistic graphical models)
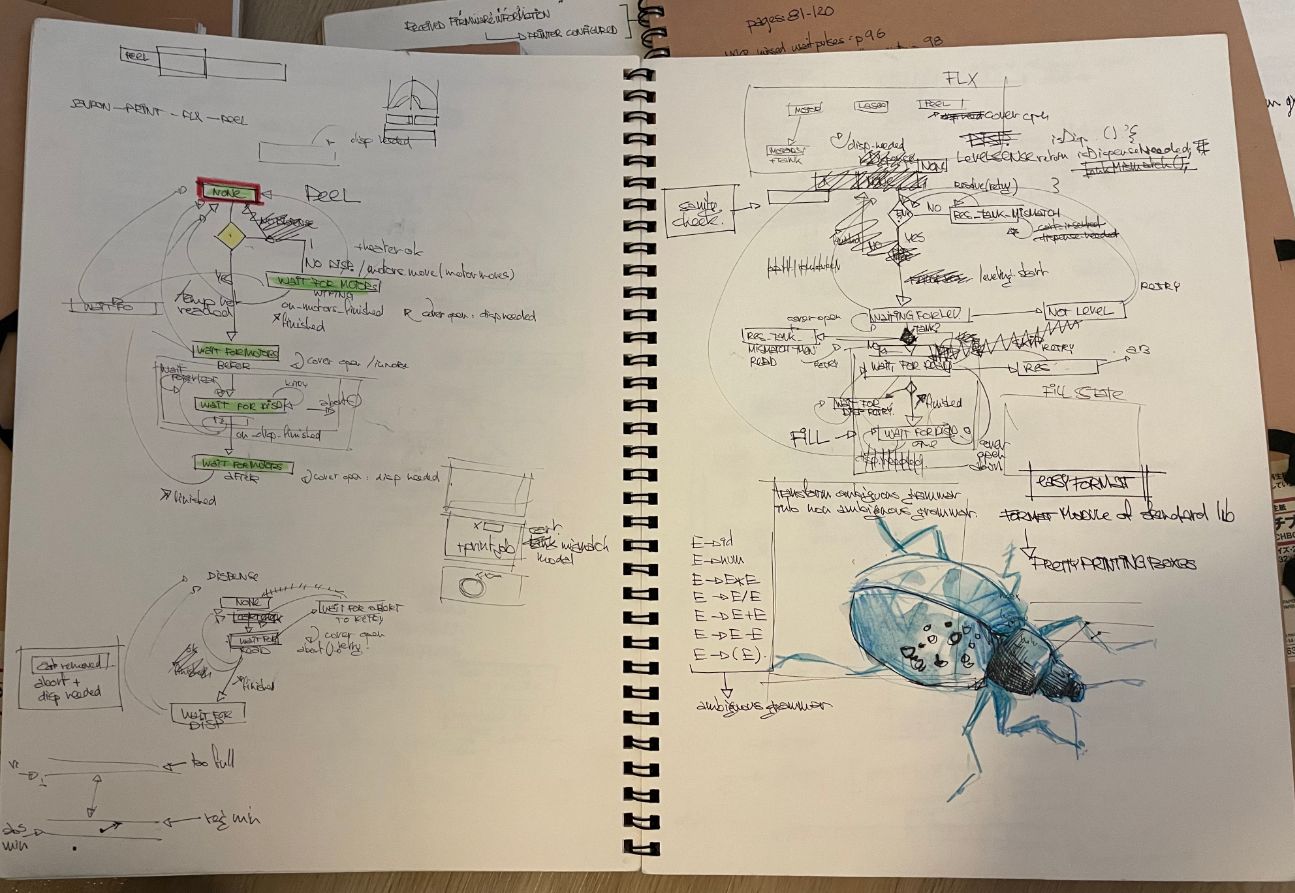
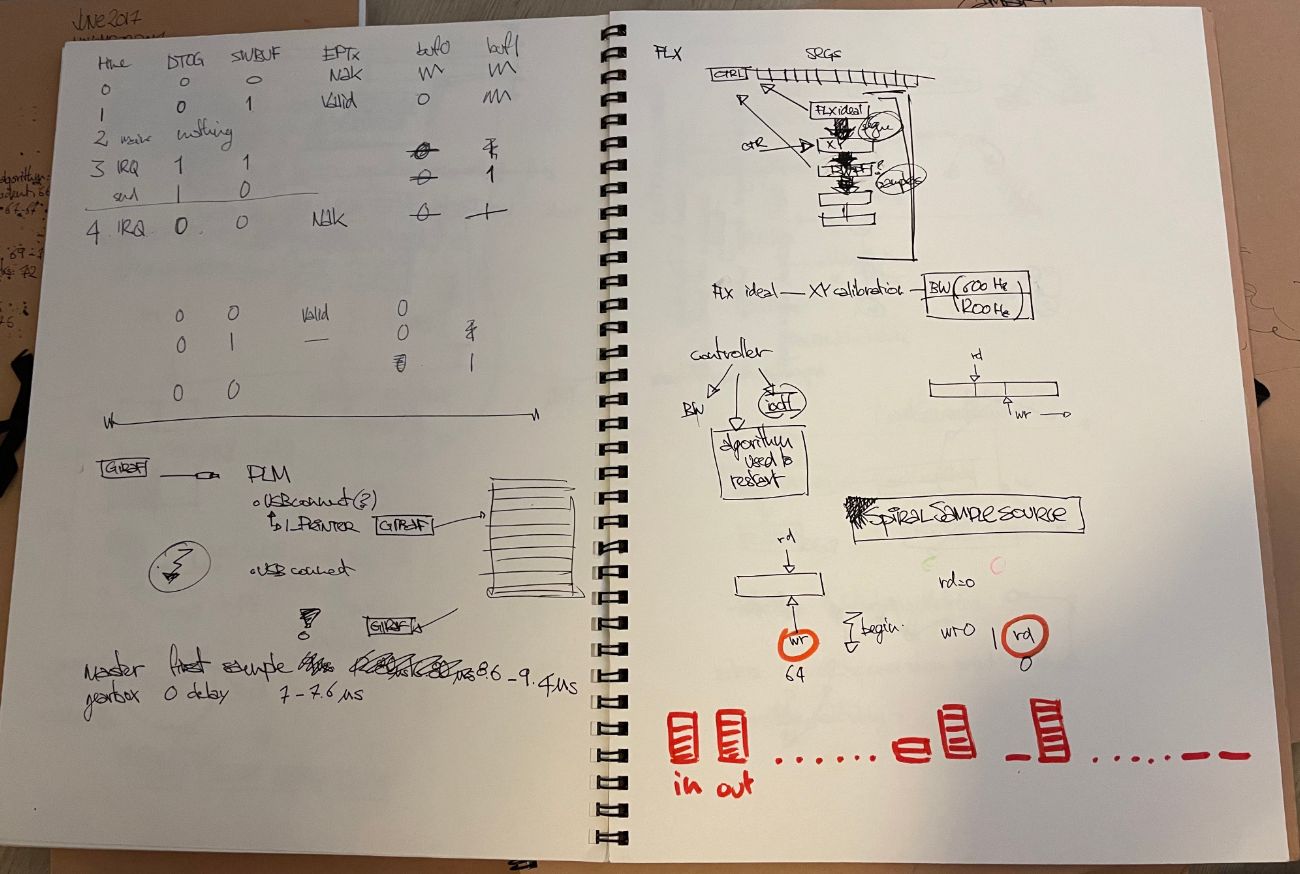
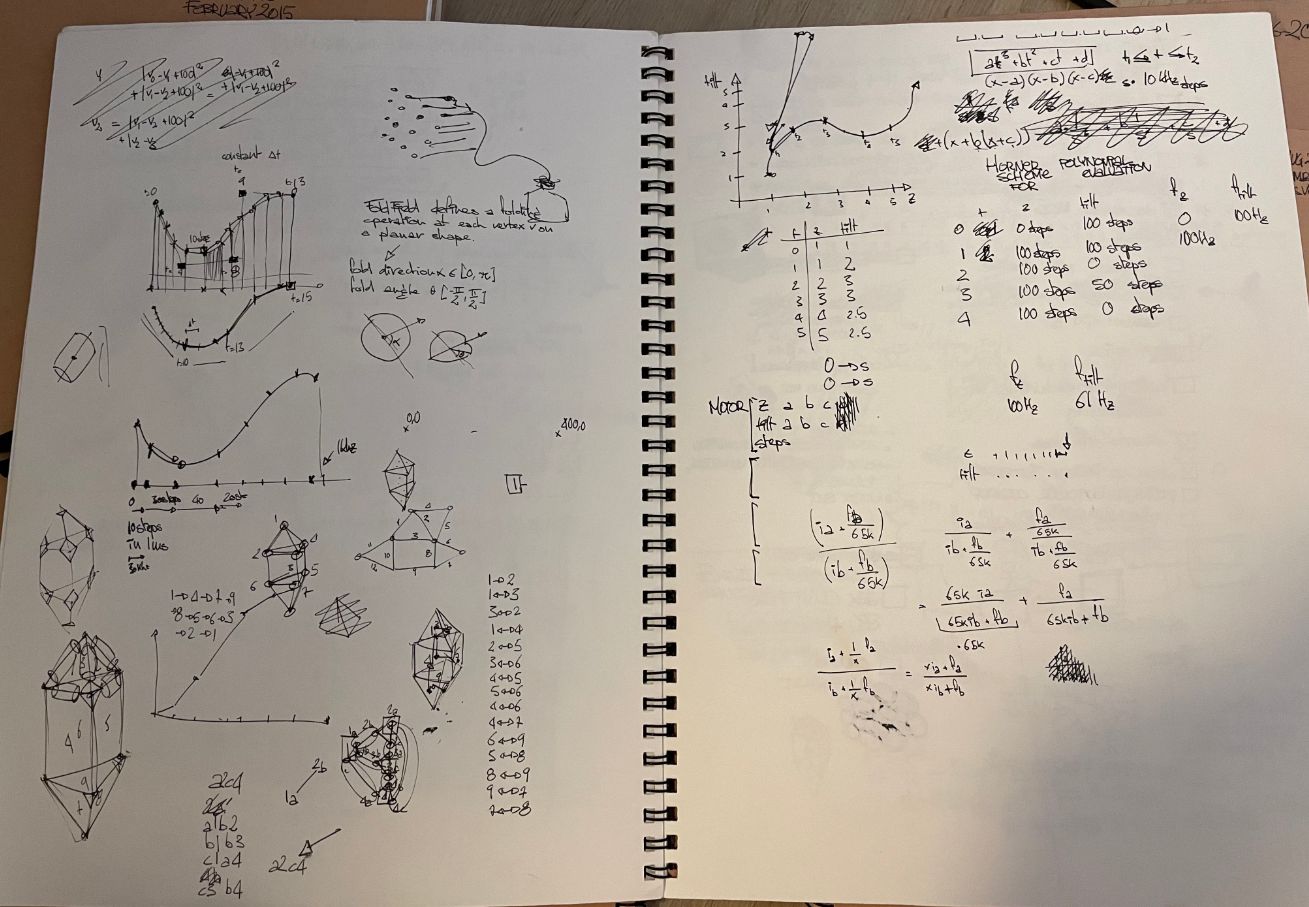
I love xstate! I do use plantuml a lot for sketching, but most is done on paper or whiteboards and is quite transient in nature. I must have hundreds if not thousands of sketchbooks pages that look like this:
I gave an Elm talk years ago at the shared office space I used to work at. A few devs there later told me the talk helped them better understand React.
Of course Elm is closely related to Haskell, which is a playground for category theory. I think learning the why behind it all can be useful in subtle ways.
Elm is a pure functional language where all data is immutable and functions are pure meaning they are guaranteed to have no side effects.
Having no side effects in JS is easy (just don't do it!) but immutability takes some effort.
React requires immutability so that if it sees the reference to an object again, it knows that it contains the same data. If it promised to work when mutating objects it would continuously need to deep search inside them to see what changed.
In JS, some array operations mutate the array, some copy it, you have to know specifically what operation you are using. In Elm, nothing mutates objects. All built in functions and functions you create will not do this.
In short - you can do (state, action) => state in any programming language, but mistakes caused by mutations are impossible in Elm by design.
This is sort of classic problem. First, you need to assume the attacker is capable of measuring checkMac's runtime reliably. Second, you also need to assume the attacker is able to control the message and the mac, but not the secret. How the attacker got there is not really relevant, the point is figuring out whether or not the system is possible to crack by having the attacker full knowledge of everything, but the secret.
In most languages, a similar implementation of checkMac would not pass the test, because they will usually implement some sort of short-circuiting. Which essentially means that checkMac will take longer to execute the closer you get to the true mac of that message.
Let's say computeMac(secret, "a") == "a21a". The attacker could pass in message="a" mac="0000" at first. Let's say that takes 1 unit of time, because "0000" == "a21a" only has to look at the first character. So the attacker knows that 0 is wrong. They then try "1000", then "2000", up until they get to "a000". Then, the algorithm takes 2 units of time, the first one is comparing '0' == 'a' and the second one is '0' == '2'. Now the attacker knows the first character of the mac. They keep going like this until they find out the entire mac of the message. In a nutshell, the time the function takes to execute leaks informartion that an attacker could use.
In this language, when you do use the secret(string) type, it will always compare all the characters of the string, even after it knows it will be false anwyay, just to make sure no information is leaked.
Dozens. The standard language has been through numerous revisions (C++ 2.0, 98, 03, 11, 14, 17, 23), with no doubt many more to come - each version is a dialect. And there have been dozens of compilers, all of which define extensions to the standard - some of those extensions are copied by other compilers (and may eventually end up in the standard), others are unique to that implementation - so each compiler (even each of its successive major releases) can be viewed as a dialect. And then there are dialects defined, not by the core language features, but by which features are used, by which external libraries are used, etc. One C++ programmer is addicted to esoteric template metaprogramming, another avoids templates and treats C++ as a slightly improved version of C. One C++ programmer uses every Boost library they possibly can, another refuses to use any third party dependencies. One uses exceptions and RTTI heavily, the other always turns them off. Aren’t those all effectively different dialects, even if they are both using the exact same version of the same tools?
And then there are entire languages defined as extensions of C++, such as Apple’s Objective C++, or Microsoft’s Managed Extensions for C++ and then C++/CLI and C++/CX - and also more modest extensions such as OpenMP
Considering C++ is an object-oriented extension to C, it belongs alongside other such extensions - most notably Objective C and D (and even, to a lesser degree, Java and C#) - and there have been other attempts at that which weren’t successful - aren’t they all (in a sense) C dialects?
A large factor in the push for C# was that MS was sued by Sun for their not-totally-compliant Java dialect, Visual J++, and had to drop it as part of a settlement.
They also had Visual J# which ran on .NET, allowing Visual J++ and Java programs to target that platform.
There is also a non-Microsoft open source implementation of Java on top of .NET, IKVM.NET - I was sad to see it die when its original developer lost interest (although I just learnt it has since been revived by others)
Nope. You can go ahead and make a startup which can fail and then you're left with burnout and an empty bank account. Wasting time is an integral part of life.
My experience has been diametrically opposite to this. I've found Stack Exchange communities to be amazing communities to ask deep questions, practice technical writing and even exercise critical thinking skills.
On the Math Exchange I've had nothing but positive experience. The thing to do is first to struggle a bit with the problem and formulate a good question. Asking good question is an incredibly valuable skill. The questions which get treated bad are usually either poorly written and/or the person asking it clearly didn't even spend the bare minimum trying to solve it.
Here are some tips to get your questions answered and upvoted:
1) Spend some time on the problem
2) Describe what you've tried and why according to you that doesn't work or you don't understand it
3) Write in clear language and don't make obvious grammar mistakes
> The questions which get treated bad are usually either poorly written and/or the person asking it clearly didn't even spend the bare minimum trying to solve it.
My thoughts on what usually happens when someones says how bad questions are treated on SO/SE. For reference here's the question referred in the document: https://math.stackexchange.com/q/1464844. Notice how the answer mentioned isn't actually an answer but a comment or, to be precise, a clarifying question since the asked question wasn't specific at all.
While i agree that asking good questions is important you've laid out 3 criteria impossible for most people to achieve. Do work, be thorough and communicate clearly.
So many people I run into cannot even identify keywords for a good web search much less formulate questions and the context needed to get the answers they need.
{kind=link}
{kind=link}
{kind=link}
{kind=link}