Looking at the htop screenshot, I notice the lack of swap. You may want to enable earlyoom, so your whole server doesn't go down when a service goes bananas. The Linux Kernel OOM killer is often a bit too late to trigger.
You can also enable zram to compress ram, so you can over-provision like the pros'. A lot of long-running software leaks memory that compresses pretty well.
Even better than earlyoom is systemd-oomd[0] or oomd[1].
systemd-oomd and oomd use the kernel's PSI[2] information which makes them more efficient and responsive, while earlyoom is just polling.
earlyoom keeps getting suggested, even though we have PSI now, just because people are used to using it and recommending it from back before the kernel had cgroups v2.
Do you have any insight in to why this isn't included by default in distros like Ubuntu. It's kind of bewildering that the default behavior on Ubuntu is to just lock up the whole system on OOM
Is there any way to get something like the oomd or zram that works on gpu memory? I run into gpu memory leaks more often. Itbseems to be electron usually.
GPU memory model quite different from CPU memory model, with application level explicit synchronization and coherency and so on. I don't think that transparent compression would be possible, and even if it would surely carry drastic perf downside
> systemd-oomd periodically polls PSI statistics for the system and those cgroups to decide when to take action.
It's unclear if the docs for systemd-oomd are incorrect or misleading; I do see from the kernel.org link that the recommended usage pattern is to use the `poll` system call, which in this context would mean "not polling", if I understand correctly.
systemd-oomd, oomd, and earlyoom all do poll for when to actually take action on OOM conditions.
What I was trying to say is that the actual information on when there's memory pressure is more accurate for systemd-oomd / oomd because they use PSI, which the kernel itself is updating over time, and they just poll that, while earlyoom is also internally making its own estimates at a lower granularity than the kernel does.
Unrelated to the topic, it seems awfully unintuitive to name a function ‘poll’ if the result is ‘not polling.’ I’m guessing there’s some history and maybe backwards-compatible rewrites?
Specifically, earlyoom’s README says it repeatedly checks (“periodically polls”) the memory pressure, using CPU each time even when there is no change. The “poll” system call waits for the kernel to notify the process that the file has changed, using no CPU until the call resolves. It’s unclear what systemd-oomd does, because it uses the phrase “periodically polls”,
Another option would be to have more memory that required over-engineer and to adjust the oom score per app, adding early kill weight to non critical apps and negative weight to important apps. oom_score_adj is already set to -1000 by OpenSSH for example.
Another useful thing to do is effecively disable over-commit on all staging and production servers (0 ratio instead of 2 memory to fully disable as these do different things, memory 0 still uses formula)
vm.overcommit_memory = 0
vm.overcommit_ratio = 0
Also use a formula to set min_free and reserved memory using a formula from Redhat that I do not have handy based on installed memory. min_free can vary from 512KB to 16GB depending on installed memory.
At least that worked for me in about 50,000 physical servers for over a decade that were not permitted to have swap and installed memory varied from 144GB to 4TB of RAM. OOM would only occur when the people configuring and pushing code would massively over-commit and not account for memory required by the kernel. Not following best practices defined by Java and thats a much longer story.
Another option is to limit memory per application in cgroups but that requires more explaining than I am putting in an HN comment.
Another useful thing is to never OOM kill in the first place on servers that are only doing things in memory and need not commit anything to disk. So don't do this on a disked database. This is for ephemeral nodes that should self heal. Wait 60 seconds so drac/ilo can capture crash message and then earth shattering kaboom...
For a funny side note, those options can also be used as a holy hand grenade to intentionally unsafely reboot NFS diskless farms when failing over to entirely different NFS server clusters. setting panic to 15 mins, triggering OOM panic by setting min_free to 16TB at the command line via Ansible not in sysctl.conf, swapping clusters, arp storm and reconverge.
That's a more complex path I avoided discussing when I referenced CGroups. When I started doing these things kube clusters did not exist. These tips were for people using bare metal that have not decided as a company to go the k3/k8 route. Some of these settings will still apply to k8 physical nodes. The good people of Hetzner would be managing these settings on their bare metal that Kubernetes is running on and would not likely want their k8 nodes getting all broken, sticky and confused after a K8 daemon update results in memory leakage, billions of orphaned processes, etc...
Companies that use k3/k8's they may still have bare metal nodes that are dedicated to a role such as databases, ceph storage nodes, DMZ SFTP servers, PCI hosts that were deemed out of scope for kube clusters and of course any "kittens" such as Linux nodes turned into proprietary appliances after installing some proprietary application that will blow chunks if shimmed into k8's or any other type of abstraction layer.
I mentioned Hetnzer only because the original article mentions it. To be fair, currently it is harder to use than any managed k8s offering because you need to deploy your control plane yourself (but fortunately there are several project that make it as easy as it can be, and this is what I was referring to).
Yeah, no way. As soon as you hit swap, _most_ apps are going to have a bad, bad time. This is well known, so much so that all EC2 instances in AWS disable it by default. Sure, they want to sell you more RAM, but it's also just true that swap doesn't work for today's expectations.
Maybe back in the 90s, it was okay to wait 2-3 seconds for a button click, but today we just assume the thing is dead and reboot.
This is a wrong belief because a) SSDs make swap almost invisible, so you can have that escape ramp if something goes wrong b) SWAP space is not solely an escape ramp which RAM overflows into anymore.
In the age of microservices and cattle servers, reboot/reinstall might be cheap, but in the long run it is not. A long running server, albeit being cattle, is always a better solution because esp. with some excess RAM, the server "warms up" with all hot data cached and will be a low latency unit in your fleet, given you pay the required attention to your software development and service configuration.
Secondly, Kernel swaps out unused pages to SWAP, relieving pressure from RAM. So, SWAP is often used even if you fill 1% of your RAM. This allows for more hot data to be cached, allowing better resource utilization and performance in the long run.
So, eff it, we ball is never a good system administration strategy. Even if everything is ephemeral and can be rebooted in three seconds.
Sure, some things like Kubernetes forces "no SWAP, period" policies because it kills pods when pressure exceeds some value, but for more traditional setups, it's still valuable.
My work Ubuntu laptop has 40GB of RAM and and a very fast Nvme SSD, if it gets under memory pressure it slows to a crawl and is for all practical purposes frozen while swapping wildly for 15-20 minutes.
So no, my experience with swap isn't that it's invisible with SSD.
I don't know your exact situation, but be sure you're not mixing up "thrashing" with "using swap". Obviously, thrashing implies swap usage, but not the other way around.
I get it that the distinction is real but nobody using the machine cares at this point. It must not happen and if disabling swap removes it then people will disable swap.
I've experimented with no-swap and find the same thing happens. I think the issue is that linux can also evict executable pages (since it can just reload them from disk).
I've had good experience with linux's multi-generation LRU feature, specifically the /sys/kernel/mm/lru_gen/min_ttl_ms feature that triggers OOM-killer when the "working set of the last N ms doesn't fit in memory".
It's seldom invisible, but in my experience how visible it is depends on the size/modularity/performance/etc of what's being swapped and the underlying hardware.
On my 8gb M1 Mac, I can have a ton of tabs open and it'll swap with minimal slowdown. On the other hand, running a 4k external display and a small (4gb) llm is at best horrible and will sometimes require a hard reset.
I've seen similar with different combinations of software/hardware.
Linux being absolute dogshit if it’s under any sort of memory pressure is the reason, not swap or no swap. Modern systems would be much better off tweaking dirty bytes/ratios, but fundamentally the kernel needs to be dragged into the XXI century sometime.
It's kind of solved since kernel 6.1 with MGLRU, see above.
Dirty buffer should also be tuned (limited), absolutely. Default is 20% of RAM, (with 5 second writeback and 30 second expire intervals), which is COMPLETELY insane. I limit it to 64 MB max usually, with 1 second writeback and 3 second expire intervals.
This is not really true of most SSDs. When Linux is really thrashing the swap it’ll be essentially unusable unless the disk is _really_ fast. Fast enough SSDs are available though. Note that when it’s really thrashing the swap the workload is 100% random 4KB reads and writes in equal quantities. Many SSDs have high read speeds and high write speeds but have much worse performance under mixed workloads.
I once used an Intel Optane drive as swap for a job that needed hundreds of gigabytes of ram (in a computer that maxed out at 64 gigs). The latency was so low that even while the task was running the machine was almost perfectly usable; in fact I could almost watch videos without dropping frames at the same time.
Do you know how the le9 patch compares to mg_lru? The latter applies to all memory, not just files as far as I can tell. The former might still be useful in preventing eager OOM while still keeping executable file-backed pages in memory?
le9 is a 'simple' method to keep the fixed amount of the page cache. It works exceptionally well for what it is, but it requires manual tuning of the amount of cache in MB.
MGLRU is basically a smarter version of already existing eviction algorithm, with evicts (or keeps) both page cache and anon pages, and combined with min_ttl_ms it tries to keep current active page cache for a specified amount of time. It still takes into account swappiness and does not operate on a fixed amount of page cache, unlike le9.
Both are effective in trashing prevention, both are different. MGLRU, especially with higher min_ttl_ms, could cause OOM killer more frequently than you'd like it to be called. I find le9 more effective for desktop use on old low-end machines, but that's only because it just keeps the (large/er amounts of) page cache. It's not very preferable for embedded systems for example.
That may be the intention, but you shouldn’t rely on it. In practice the average IO size is, or at least was, almost always 4KB.
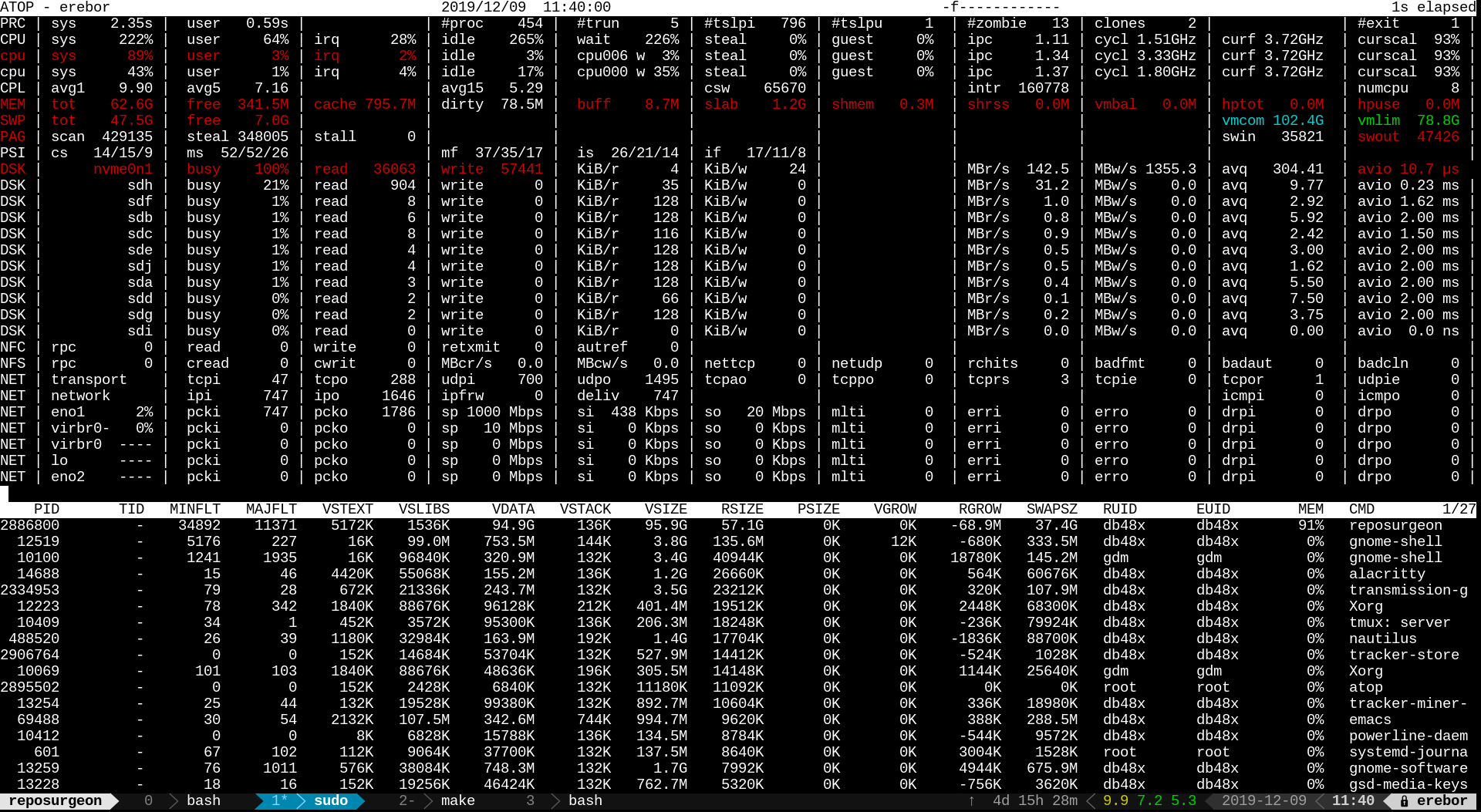
Here’s a screenshot from atop while the task was running: <https://db48x.net/temp/Screenshot%20from%202019-11-19%2023-4...>. Note the number of page faults, the swin and swout (swap in and swap out) numbers, and the disk activity on nvme0n1. Swap in is 150k, and the number of disk reads was 116k with an average size of 6KB. Swap out was 150k with 150k disk writes of 4KB. It’s also reading from sdh at a fair clip (though not as fast as I wanted!)
<https://db48x.net/temp/Screenshot%20from%202019-12-09%2011-4...> is interesting because it actually shows 24KB average write size. But notice that swout is 47k but there were actually 57k writes. That’s because the program I was testing had to write data out to disk to be useful, and I had it going to a different partition on the same nvme disk. Notice the high queue depth; this was a very large serial write. The swap activity was still all 4KB random IO.
That's surprising. Do you know what your application memory access pattern is like, is it really this random and the single page io is working along its grain, or is the page clustering, io readahead etc just MIA?
I didn’t delve very deep into it, but the program was written in Go. At this point in the lifecycle of the program we had optimized it quite a bit, removing all the inefficiencies that we could. It was now spending around two thirds of its cpu cycles on garbage collection. It had this ridiculously large heap that was still growing, but hardly any of it was actually garbage.
I rewrote a slice of the program in Rust with quite promising results, but by that time there wasn’t really any demand left. You see, one of the many uses of Reposurgeon <http://www.catb.org/esr/reposurgeon/> is to convert SVN repositories into Git repositories. These performance results were taken while reposurgeon was running on a dump of the GCC source code repository. At the time this was the single largest open source SVN repository left in the world with 287k commits. Now that it’s been converted to a Git repository it’s unlikely that future Reposurgeon users will have the same problem.
Also, someone pointed out that MG-LRU <https://docs.kernel.org/admin-guide/mm/multigen_lru.html> might help by increasing the block size of the reads and writes. It was introduced a year or more after I took these screenshots, so I can’t easily verify that.
How long is long running? You should be getting the warm caches after at most a few hours.
> Secondly, Kernel swaps out unused pages to SWAP, relieving pressure from RAM. So, SWAP is often used even if you fill 1% of your RAM. This allows for more hot data to be cached, allowing better resource utilization and performance in the long run.
Yes, and you can observe that even in your desktop at home (if you are running something like Linux).
> So, eff it, we ball is never a good system administration strategy. Even if everything is ephemeral and can be rebooted in three seconds.
I wouldn't be so quick. Google ran their servers without swap for ages. (I don't know if they still do it.) They decided that taking the slight inefficiency in memory usage, because they have to keep the 'leaked' pages around in actual RAM, is worth it to get predictability in performance.
For what it's worth, I add generous swap to all my personal machines, mostly so that the kernel can offload cold / leaked pages and keep more disk content cached in RAM. (As a secondary reason: I also like to have a generous amount of /tmp space that's backed by swap, if necessary.)
With swap files, instead of swap partitions, it's fairly easy to shrink and grow your swap space, depending on what your needs for free space on your disk are.
> Yes, and you can observe that even in your desktop...
Yup, that part of my comment was culmination of using Linux desktops for the last two decades. :)
> I wouldn't be so quick. Google ran their servers without swap for ages.
If you're designing this from get go and planning accordingly, it doesn't fit into my definition of eff it, we ball, but let's try this and see whether we can make it work.
> With swap files, instead of swap partitions,...
I'm a graybeard. I eyeball a swap partition size while installing the OS, and just let it be. Being mindful and having good amount of RAM means that SWAP acts as a eviction area for OS first, and as an escape ramp second, in very rare cases.
It doesn't. SSDs came a long way but so did memory dies and buses, and with that the way programs work also changed as more and more they are able to fit their stacks and heaps on memory more often than not.
I have had a problem with shellcheck that for some reason eats up all my ram when I open I believe .zshrc and trust me, it's not invisible. The system crawls to a halt.
If we're talking about SATA SSDs which top at 600MBps, then yes, an aggressive application can make itself known. However, if you have a modern NVMe, esp. a 4x4 one like Samsung 9x0 series or if you're using a Mac, I bet you'll notice the problem much later, if ever. Remember the SSD trashing problem on M1 Macs? People never noticed that system used SWAP that heavily and trashed the SSD on board.
Then, if you're using a server with a couple of SAS or NVMe SSDs, you'll not notice the problem again, esp. if these are backed by RAID (even md counts).
Now that you say, I have a new Lenovo yoga with those SoC ram with crazy parallel channel config (16gb spread across 8 dies of 2gb). It's noticeably faster than my Acer nitro with dual channel 16gb ddr5. I'll check that, but I'd say it's not what the average home user (and even server I'd risk saying) would have.
> it's not invisible. The system crawls to a halt.
I’m gonna guess you’re not old enough to remember computers with memory measured in MB and IDE hard disks? Swapping was absolutely brutal back then. I agree with the other poster, swap hitting an SSD is a barely noticeable in comparison.
I think I've not made myself as clear as I could. Swap is important for efficient system performance way before you hit OOM on main memory. It's not, however, going to save system responsiveness in case of OOM. This is what I mean.
The trade-off depends on how your system is set up.
Eg Google used to (and perhaps still does?) run their servers without swap, because they had built fault tolerance in their fleet anyway, so were happier to deal with the occasional crash than with the occasional slowdown.
For your desktop at home, you'd probably rather deal with a slowdown that gives you a chance to close a few programs, then just crashing your system. After all, if you are standing physically in front of your computer, you can always just manually hit the reset button, if the slowdown is too agonising.
Swap delays the 'fundamental issue', if you have a leak that keeps growing.
If your problem doesn't keep growing, and you just have more data that programs want to keep in memory than you have RAM, but the actual working set of what's accessed frequently still fits in RAM, then swap perfectly solves this.
Think lots of programs open in the background, or lots of open tabs in your browser, but you only ever rapidly switch between at most a handful at a time. Or you are starting a memory hungry game and you don't want to be bothered with closing all the existing memory hungry programs that idle in the background while you play.
I run a chat server on a small instance; when someone uploads a large image to the chat, the 'thumbnail the image' process would cause the OOM-killer to take out random other processes.
Adding a couple of gb of swap means the image resizing is _slow_, but completes without causing issues.
The problem is freezing the system for hours or more to delay the issue is not worth it. I'd rather a program get killed immediately than having my system locked up for hours before a program gets killed.
The fundamental issue here is what the linux fanboys literally think what killing a working process and most of the time the process[0] is a good solution for not solving the fundamental problem of memory allocation in the Linux kernel.
Availability of swap allows you to avoid malloc failure in a rare case your processes request more memory than physically (or 'physically', heh) present in the system. But in the mind of so called linux administrators even if a one byte of the swap would be used then the system would immediately crawl to a stop and never would recover itself. Why it always should be the worst and the most idiotic scenario instead of a sane 'needed 100MB more, got it - while some shit in the memory which wasn't accessed since the boot was swapped out - did the things it needed to do and freed that 100MB' is never explained by them.
[0] imagine a dedicated machine for *SQL server - which process would have the most memory usage on that system?
Also: When those processes that haven't been active since boot (and which may never be active again) are swapped out, more system RAM can become available for disk caching to help performance of things that are actively being used.
And that's... that's actually putting RAM to good use, instead of letting it sit idle. That's good.
(As many are always quick to point out: Swap can't fix a perpetual memory leak. But I don't think I've ever seen anyone claim that it could.)
What if I care more about the performance of things that aren't being used right now than the things that are? I'm sick of switching to my DAW and having to listen to my drive thrash when I try to play a (say) sampler I had loaded.
Detecting things are down is far easier than detecting things are slow.
I'd rather that oom started killing things though than a kernel panic or a slow system. Ideally the thing that is leaking, but if not the process using the most memory (and yes I know that "using" is tricky)
I don't count crawling to a halt as a working machine. Plus it depends. Back in the day I had computers that got blocked for 30-ish seconds which was annoying but gave you the window of opportunity to go kill the offending program. But then you had some that we left, out of curiosity, to work throughout the entire workday and they never recovered.
So most of the time I'd prefer option 3: the OOM killer to reap a few offending programs and let me handle restarting them.
From my understanding, the comment I'm replying to uses EC2 example to portray that swapping is wrong in any and all circumstances, and I just replied with my experience with my system administrator hat.
I'm not an AWS guy. I can see and touch the servers I manage, and in my experience, SWAP works, and works well.
Just for context EC2 typically uses network storage that, for obvious reasons, often has fairly rubbish latency and performance characteristics. Swap works fine if you have local storage, though obviously it burns through your SSD/NVME drive faster and can other side effects on it's performance (usually not particularly noticeable).
Thanks, I'll keep that in mind if I start to use EC2 for workloads.
However, from my experience, normal (eviction based) usage of SWAP doesn't impact the life of an SSD in a measurable manner. My 256GB system SSD (of my desktop system) shows 78% life remaining after 4 years of power on hours, which also served as /home for at least half of its life.
You don't care about life of any hardware in the cloud, that doesn't really matter either unless you work for the cloud provider in their datacenter teams.
A long running Linux system uses 100% of its RAM. Every byte unused for applications will be used as a disk cache, given you read more data than your total RAM amount.
This cache is evictable, but it'll be there eventually.
Linux used to don't touch unused pages in the RAM in the older days if your RAM was not under pressure, but now it swaps out pages unused for a long time. This allows more cache space in RAM.
> how does caching to swap help?
I think I failed to convey what I tried to say. Let me retry:
Kernel doesn't cache to SSD. It swaps out unused (not accessed) but unevictable pages to SWAP, assuming that these pages will stay stale for a very long time, allowing more RAM to be used as cache.
When I look to my desktop system, in 12 days, Kernel moved 2592MB of my RAM to SWAP despite having ~20GB of free space. ~15GB of this free space is used as disk cache.
So, to have 2.5GB more disk cache, Kernel moved 2592 MB of non-accessed pages to SWAP.
Yes, and if I am writing an API service, for example, I don’t want to suddenly add latency because I hit pages that have been swapped out. I want guarantees about my API call latency variance, at least when the server isn’t overloaded.
I DON’T WANT THE KERNEL PRIORITIZING CACHE OVER NRU PAGES.
You better not write your API in Python, or any language/library that uses amortised algorithms in the standard (like Rust and C++ do). And let's not mention garbage collection.
If you're getting this far into the details of your memory usage, shouldn't you use mlock to actually lock in the parts of memory you need to stay there? Then you get to have three tiers of priority: pages you never want swapped, cache, then pages that haven't been used recently.
If you’re writing services in anything higher level than C you’re leaking something somewhere that you probably have no idea exists and the runtime won’t ever touch again.
That’s a fair question. A page is the smallest allocatable unit of RAM, from the OS/kernel perspective. The size is set by the CPU, traditionally 4kB, but these days 8kB-4MB are also common.
When you call malloc(), it requests a big chunk of memory from the OS, in units of pages. It then uses an allocator to divide it up into smaller, variable length chunks to form each malloc() request.
You may have heard of “heap” memory vs “stack” memory. The stack of course is the execution/call stack, and heap is called that because the “heap allocator” is the algorithm originally used for keeping track of unused chunks of these pages.
(This is beginner CS stuff so sorry if it came off as patronizing—I assume you’re either not a coder or self-taught, which is fine.)
You already maxed it from Kernel's PoV.
8GB of RAM, where 6.8GB is cache. ~700MB is resident and 459 is free because I assume Kernel wants to have some free space to allocate something quite fast.
25MB swap use seems normal for a server which doesn't juggle much tasks, but works on one.
If you are interested in human consumption, there's "free --human" which decided on useful units by itself. The "--human" switch is also available for "du --human" or "df --human" or "ls -l --human". It's often abbreviated as "-h", but not always, since that also often stands for "--help".
Thanks, I generally use free -m since my brain can unconsciously parse it after all these years. ls -lh is one of my learned commands though. I type it in automatically when analyzing things.
ls -lrt, ls -lSh and ls -lShr are also very common in my daily use, depending on what I'm doing.
So that 2M of used swap is completely irrelevant. Same on my laptop
total used free shared buff/cache available
Mem: 31989 11350 4474 2459 16164 19708
Swap: 6047 20 6027
My syslog server on the other hand (which does a ton of stuff on disk) does use swap
Mem: 1919 333 75 0 1511 1403
Swap: 2047 803 1244
With uptime of 235 days.
If I were to increase this to 8G of ram instead of 2G, but for arguments sake had to have no swap as the tradeoff, would that be better or worse. Swap fans say worse.
> So that 2M of used swap is completely irrelevant.
As I noted somewhere, my other system has 2,5GB of SWAP allocated over 13 days. That system is a desktop system and juggles tons of things everyday.
I have another server with tons of RAM, and the Kernel decided not to evict anything to SWAP (yet).
> If I were to increase this to 8G of ram instead of 2G, but for arguments sake had to have no swap as the tradeoff, would that be better or worse. Swap fans say worse.
I'm not a SWAP fan, but I support its use. On the other hand I won't say it'd be worse, but it'd be overkill for that server. Maybe I can try 4, but that doesn't seem to be necessary if these numbers are stable over time.
The OS uses almost all the ram in your system (it just doesn't tell you because then users complain that their OS is too ram heavy). The primary thing it uses it for is caching as much of your storage system as possible. (e.g. all of the filesystem metadata and most of the files anyone on the system has touched recently). As such, if you have RAM that hasn't been touched recently, the OS can page it out and make the rest of the system faster.
At the cost of tanking performance for the less frequently used code path. Sometimes it is more important to optimize in ways that minimize worst case performance rather than a marginal improvement to typical work loads. This is often the case for distributed systems, e.g. SaaS backends.
This is not about belief, but lived experience. Setting up swap to me is a choice between a unresponsive system (with swap) or a responsive system with a few oom kills or downed system.
Swap also works really well for desktop workloads. (I guess that's why Apple uses it so heavily on their Macbooks etc.)
With a good amount of swap, you don't have to worry about closing programs. As long as your 'working set' stays smaller than your RAM, your computer stays fast and responsive, regardless of what's open and idling in the background.
It doesn’t happen often, and I have a multi user system with unpredictable workloads. It’s also not about swap filling up, but giving the pretense the system is operable in a memory exhausted state which means oom killer doesn’t run, but the system is unresponsive and never recovers.
Without swap oom killer runs and things become responsive.
>It's a bit wasteful to provision your computers so that all the cold data lives in expensive RAM.
But that's a job applications are already doing. They put data that's being actively worked on in RAM they leave all the rest in storage. Why would you need swap once you can already fit the entire working set in RAM?
Because then you have more active working memory as infrequently used pages are moved to compressed swap and can be used for more page cache or just normal resident memory.
Swap ram by itself would be stupid but no one doing this isn’t also turning on compression.
> Swap ram by itself would be stupid but no one doing this isn’t also turning on compression.
I'm not sure what you mean here? Swapping out infrequently accesses pages to disk to make space for more disk cache makes sense with our without compression.
Swapping out to RAM without compression is stupid - then you’re just shuffling pages around in memory. Compression is key so that you free up space. Swap to disk is separate.
>Because then you have more active working memory as infrequently used pages are moved to compressed swap and can be used for more page cache or just normal resident memory.
Uhh... A VMM that swaps out to disk an allocated page to make room for more disk cache would be braindead. The process has allocated that memory to use it. The kernel doesn't have enough information to deem disk cache a higher priority. The only thing that should cause it to be swapped out is either another process or the kernel requesting memory.
> A VMM that swaps out to disk an allocated page to make room for more disk cache would be braindead
Claiming any decision is “brain dead” in something as heuristic heavy and impossible to compute optimally as resident memory pages is quite the statement to make; this is a form of the knapsack problem (NP-complete at least) with the added benefit of time where the items are needed in some specific indeterminate order in the future and there’s a whole bunch of different workloads and workload permutations that alter this.
To drive this point home in case you disagree, what’s dumber? Swapping out to disk an allocated page (from the kernel’s perspective) that’s just sitting in the free list of the userspace allocator for that process or a page of some frequently accessed page of data?
Now, I agree that VMMs may not do this because it’s difficult to come up with these kinds of scenarios that don’t penalize the general case, more importantly than performance this has to be a mechanism that is explainable to others and understandable for them. But claiming it’s a braindead option to even consider is IMHO a bridge too far.
You mean to tell me most applications you've ever used read the entire file system, loading every file into memory, and rely on the OS to move the unused stuff to swap?
A silly but realistic example: lots of applications leak a bit of memory here and there.
Almost by definition, that leaked memory is never accessed again, so it's very cold. But the applications don't put this on disk by themselves. (If the app's developers knew about which specific bit is leaking, they'd rather fix the leak then write it to disk.)
That's just recognizing that there's a spectrum of hotness to data. But the question remains: if all the data that the application wants to keep in memory does fit in memory, why do you need swap?
> Running out of memory kills performance. It is better to kill the VM and restart it so that any active VM remains low latency.
Right, you seem to be not understanding what I'm getting at.
Memory exhaustion is bad, regardless of swap or not.
Swap gets you a better performing machine because you can swap out shit to disk and use that ram for vfs cache.
the whole "low latency" and "I want my VM to die quicker" is tacitly saying that you haven't right sized your instances, your programme is shit, and you don't have decent monitoring.
Like if you're hovering on 90% ram used, then your machine is too small, unless you have decent bounds/cgroups to enforce memory limits.
Many won't enable swap. For some swap wouldn't help anyways, but others it could help soak up spikes. The latter in some cases will upgrade to a larger instance without even evaluating if swap could help, generating AWS more money.
Either way it's far-fetched to derive intention from the fact.
"as soon as you hit swap" is a bad way of looking at things. Looking around at some servers I run, most of them have .5-2GB of swap used despite a bunch of gigabytes of free memory. That data is never or almost never going to be touched, and keeping it in memory would be a waste. On a smaller server that can be a significant waste.
Swap is good to have. The value is limited but real.
Also not having swap doesn't prevent thrashing, it just means that as memory gets completely full you start dropping and re-reading executable code over and over. The solution is the same in both cases, kill programs before performance falls off a cliff. But swap gives you more room before you reach the cliff.
How programs use ram also changed from the 90s. Back then they were written targeting machines that they knew would have a hard time fitting all their data in memory, so hitting swap wouldn't hurt perceived performance too drastically since many operations were already optimized to balance data load between memory and disk.
Nowadays when a program hits swap it's not going to fallback to a different memory usage profile that prioritises disk access. It's going to use swap as if it were actual ram, so you get to see the program choking the entire system.
If your GC is a moving collector, then absolutely this is something to watch out for.
There are, however, a number of runtimes that will leave memory in place. They are effectively just calling `malloc` for the objects and `free` when the GC algorithm detects an object is dead.
Go, the CLR, Ruby, Python, Swift, and I think node(?) all fit in this category. The JVM has a moving collector.
Every garbage collector has to constantly sift through the entire reference graph of the running program to figure out what objects have become garbage. Generational GC's can trace through the oldest generations less often, but that's about it.
Tracing garbage collectors solve a single problem really really well - managing a complex, possibly cyclical reference graph, which is in fact inherent to some problems where GC is thus irreplaceable - and are just about terrible wrt. any other system-level or performance-related factor of evaluation.
> Every garbage collector has to constantly sift through the entire reference graph of the running program to figure out what objects have become garbage.
There's a lot of "it depends" here.
For example, an RC garbage collector (Like swift and python?) doesn't ever trace through the graph.
The reason I brought up moving collectors is by their nature, they take up a lot more heap space, at least 2x what they need. The advantage of the non-moving collectors is they are much more prompt at returning memory to the OS. The JVM in particular has issues here because it has pretty chunky objects.
> The reason I brought up moving collectors is by their nature, they take up a lot more heap space, at least 2x what they need.
If the implementer cares about memory use it won't. There are ways to compact objects that are a lot less memory-intensive than copying the whole graph from A to B and then deleting A.
It doesn't matter. The GC does not know what heap allocations are in memory vs swap, and since you don't write applications thinking about that, running a VM with a moving GC on swap is a bad idea.
Yeah but in practice I'm not sure that really works well with any GCs today? Ive tried this with modern JVM and Node vms, it always ended up with random multi second lockups. Not worth the time.
MemBalancer is a relatively new analysis paper that argues having swap allows maximum performance by allowing small excesses, that avoids needing to over-provision ram instead. The kind of gc does not matter since data spends very little time in that state and on the flip side, most of the time the application has twice has access to twice as much memory to use
Python’s not a mover but the cycle breaker will walk through every object in the VM.
Also since the refcounts are inline, adding a reference to a cold object will update that object. IIRC Swift has the latter issue as well (unless the heap object’s RC was moved to the side table).
A moving collector has to move to somewhere and, generally by it's nature, it's constantly moving data all across the heap. That's what makes it end up touching a lot more memory while also requiring more memory. On minor collections I'll move memory between 2 different locations and on major collections it'll end up moving the entire old gen.
It's that "touching" of all the pages controlled by the GC that ultimately wrecks swap performance. But also the fact that moving collector like to hold onto memory as downsizing is pretty hard to do efficiently.
Non-moving collectors are generally ultimately using C allocators which are fairly good at avoiding fragmentation. Not perfect and not as fast as a moving collector, but also fast enough for most use cases.
Java's G1 collector would be the worst example of this. It's constantly moving blocks of memory all over the place.
> It's that "touching" of all the pages controlled by the GC that ultimately wrecks swap performance. But also the fact that moving collector like to hold onto memory as downsizing is pretty hard to do efficiently.
The memory that's now not in use, but still held onto, can be swapped out.
This is really interesting and I've never really heard about this. What is going on with the kernel team then? Are they just going to keep swap as-is for backwards compatibility then everyone else just disables it? Or if this advice just for high performance clusters?
No. I use swap for my home machines. Most people should leave swap enabled. In fact I recommend the setup outlined in the kernel docs for tmpfs: https://docs.kernel.org/filesystems/tmpfs.html which is to have a big swap and use tmpfs for /tmp and /var/tmp.
As someone else said, swap is important not only in the case the system exhaust main memory, but it's used to efficiently use system memory before that (caching, offload page blocks to swap that aren't frequently used etc...)
The beauty of ZRAM is that on any modern-ish CPU it's surprisingly fast. We're talking 2-3 ms instead of 2-3 seconds ;)
I regularly use it on my Snapdragon 870 tablet (not exactly a top of the line CPU) to prevent OOM crashes (it's running an ancient kernel and the Android OOM killer basically crashes the whole thing) when running a load of tabs in Brave and a Linux environment (through Tmux) at the same time.
ZRAM won't save you if you do actually need to store and actively use more than the physical memory but if 60% of your physical memory is not actively used (think background tabs or servers that are running but not taking requests) it absolutely does wonders!
On most (web) app servers I happily leave it enabled to handle temporary spikes, memory leaks or applications that load a whole bunch of resources that they never ever use.
I'm also running it on my Kubernetes cluster. It allows me to set reasonable strict memory limits while still having the certainty that Pods can handle (short) spikes above my limit.
My understanding was that if you're doing random access - ZRAM has near-zero overhead. While data is being fetched from RAM, you have enough cycles to decompress blocks.
My 2cents is that in a lot of cases swap is being used for unimportant stuff leave more RAM for your app. Do a "ps aux" and look at all the RAM used by weird stuff. Good news is those things will be swapped out.
Example on my personal VPS
$ free -m
total used free shared buff/cache available
Mem: 3923 1225 328 217 2369 2185
Swap: 1535 1335 200
It's not just 3 seconds for a button click, every time I've run out of RAM on a Linux system, everything locks up and it thrashes. It feels like 100x slowdown. I've had better experiences when my CPU was underclocked to 20% speed. I enable swap and install earlyoom. Let processes die, as long as I can move the mouse and operate a terminal.
Yup, this is a thing. It happens because file-backed program text and read-only data eventually get evicted from RAM (to make room for process memory) so every access to code and/or data beyond the current 4K page can potentially involve a swap-in from disk. It would be nice if we had ways of setting up the system so that pages of code or data that are truly critical for real-time responsiveness (including parts of the UI) could not get evicted from RAM at all (except perhaps to make room for the OOM reaper itself to do its job) - but this is quite hard to do in practice.
Is it possible you misread the comment you're replying to? They aren't recommending adding swap, they're recommending adjusting the memory tunables to make the OOM killer a bit more aggressive so that it starts killing things before the whole server goes to hell.
> Maybe back in the 90s, it was okay to wait 2-3 seconds for a button click, but today we just assume the thing is dead and reboot.
My experience is the exact opposite. If anything 2-3 second button clicks are more common than ever today since everything has to make a roundtrip to a server somewhere whereas in the 90s 2-3s button click meant your computer was about to BSOD.
Edit: Apple recently brought "2-3s to open tab" technology to Safari[1].
in either case, what do you do? if you can't reach a box and it's otherwise safe to do so, you just reboot it. so is it just a matter of which situation occurs more often?
The thing is you can survive memory exhaustion if the oom killer can do its job, which it can't many times when there's swap. I guess the topmost response to this thread talks about an earlyoom tool that might alleivate this, but I've never used it, and I don't find swap helpful anyway so there's no need for me to go down this route.
YMMV. Garbage-collected/pointer-chasing languages suffer more from swapping because they touch more of the heap all the time. AWS suffers more from swap because EBS is ridiculously slow and even their instance-attached NVMe is capped compared physical NVMe sticks.
Does HDD vs SSD matter at all these days? I can think of certain caching use-cases where swapping to an SSD might make sense, if the access patterns were "bursty" to certain keys in the cache
It's still extremely slow and can cause very unpredictable performance. I have swap setup with swappiness=1 on some boxes, but I wouldn't generally recommend it.
what an ignorant and clueless comment. Guess what? Todays disks are NVMe drives which are orders of magnitude faster than the 5400rpm HDDs of the 90s. Today's swap is 90s RAM.
I have also seen this in Androids (I tested this on multiple devices - S23U, OnePlus 6,8) , whenever I completely turned off the swap , the phone after a day or two of heavy usage would sometimes hang!
It felt unintuitive since these devices had lot of RAM, and they shouldn't need swap . But turning off swap has always degraded performance for me.
Because some portion of the RAM used by your daemons isn't actually being accessed, and using that RAM to store file cache is actually a better use than storing idle memory. The old rule about "as much swap as main memory" definitely doesn't hold any more, but a few GB to store unneeded wired memory to dedicate more room to file cache is still useful.
As a small example from a default Ubuntu installation, "unattended-upgrades" is holding 22MB of RSS, and will not impact system performance at all if it spends next week swapped out. Bigger examples can be found in monolithic services where you don't use some of the features but still have to wire them into RAM. You can page those inactive sections of the individual process into swap, and never notice.
There is absolutely no point to doing that, which is why file cache is never swapped out. The swapped part is not-recently-used, wired memory from processes, so that there is more room for file cache.
Like a highway brake failure ramp, you have room for handling failures gentler. So services don't just get outright killed. If you monitor your swap usage, any usage of swap gives you early warning that your services require more memory already.
Gives you some time to upgrade, or tune services before it goes ka-boom.
If your memory usage is creeping up, the way you'll find out that you need more memory is by monitoring memory usage via the same mechanisms you'd hypothetically use to monitor your swap usage.
If your memory usage spikes suddenly, a nominal amount of swap isn't stopping anything from getting killed; you're at best buying yourself a few seconds, so unless you spend your time just staring at the server, it'll be dead anyways.
Some workloads may do better with zswap. Cache is compressed, and pages evicted to disk based swap on an LRU basis.
The case of swap thrashing sounds like a misbehaving program, which can maybe be tamed by oomd.
System responsiveness though needs a complete resource control regime in place, that preserves minimum resources for certain critical processes. This is done with cgroupsv2. By establishing minimum resources, the kernel will limit resources for other processes. Sure, they will suffer. That’s the idea.
Yeah I had a few servers look up on me without any clear way to recovery because some app was eating up ram. I am ok with the server coming to a crawl as soon as the swap has to be used but at least it won't stop responding all together.
Of course swap should be enabled. But oom killer has always allowed access to an otherwise unreachable system. The pause is there so you can impress your junior padawan who rushed to you in a hurry.
sometimes swap seems to accumulate even though there is plenty of ram. It is too "greedy" by default, probably set for desktops not servers in mind.
Therefore it is better to always tune "vm.swappiness" to 1 in /etc/sysctl.conf
You can also configure your web server / TCP stack buffers / file limits so they never allocate memory over the physical ram available. (eg. in nginx you can setup worker/connection limits and buffer sizes.)
Depends on the algorithm (and how much CPU is in use); if you have a spare CPU, the faster algorithms can more-or-less keep up with your memory bandwidth, making the overhead negligible.
And of course the overhead is zero when you don't page-out to swap.
> zram, formerly called compcache, is a Linux kernel module for creating a compressed block device in RAM, i.e. a RAM disk with on-the-fly disk compression. The block device created with zram can then be used for swap or as a general-purpose RAM disk
To clarify OP's represention of the tool, it compresses swap space not resident ram. Outside of niche use-cases, compressing swap has overall little utility.
Incorrect, with zram you swap ram to compressed ram.
It has the benefit of absorbing memory leaks (which for whatever reason compress really well) and compressing stale memory pages.
Under actual memory pressure performance will degrade. But in many circumstances where your powerful CPU is not fully utilized you can 2x or even 3x your effective RAM (you can opt for zstd compression). zram also enables you to make the trade-off of picking a more powerful CPU for the express purpose of multiplying your RAM if the workload is compatible with the idea.
PS: On laptops/workstations, zram will not interfere with an SSD swap partition if you need it for hibernation. Though it will almost never be used for anything else if you configure your zram to be 2x your system memory.
> Incorrect, with zram you swap ram to compressed ram.
That reads like what they said? You reserve part of the RAM as a swap device, and memory is swapped from resident RAM to the swap ramdisk, as long as there’s space on there. And AFAIK linux will not move pages between swap devices because it doesn’t understand them beyond priority.
Zswap actually seems strictly better in many cases (especially interactive computers / dev machines) as it can more flexibly grow / shrink, and can move pages between the compressed RAM cache and the disk swap.
Swap to disk involves a relatively small pipe (usually 10x smaller than RAM). So instead of paying the cost to page out to disk immediately, you create compressed pages and store that in a dedicated RAM region for compressed swap.
This has a number of benefits: in practice more “active” space is freed up as unused pages are compressed and often compressible. Often times that can be freed application memory that is reserved within application space but in the free space of the allocator, especially if that allocator zeroes it those pages in the background, but even active application memory (eg if you have a browser a lot of the memory is probably duplicated many times across processes). So for a usually invisible cost you free up more system RAM. Additionally, the overhead of the swap is typically not much more than a memcpy even compressed which means that you get dedup and if you compressed erroneously (data still needed) paging it back in is relatively cheap.
It also plays really well with disk swap since the least frequently used pages of that compressed swap can be flushed to disk leaving more space in the compressed RAM region for additional pages. And since you’re flushing retrieving compressed pages from disk you’re reducing writes on an SSD (longevity) and reducing read/write volume (less overhead than naiive direct swap to disk).
Basically if you think of it as tiered memory, you’ve got registers, l1 cache, l2 cache, l3 cache, normal RAM, compressed swap RAM, disk swap - it’s an extra interim tier that makes the system more efficient.
"The practice of System and Network administration" by Tom Limoncelli and Christine Hogan[1] was, together with "Principles of Network and Systems Administration" by Mark Burgess have probably been the books that influenced my approach to sysadmin the most. I still have them. Between them they covered at a high level (at least back when I was sysadmin before devops and Kubernets etc) anything and everything from
- hardware, networks, monitoring, provisioning, server room locations in existing buildings, how to prepare server rooms
- and so on up to hiring and firing sysadmins, salary negotiations[2], vendor negotiations and the first book even had a whole chapter dedicated to "Being happy"
[1] There is a third author as well now, but those two were the ones that are on the cover of my book from 2005 and that I can remember
[2] Has mostly worked well after I more or less left sysadmin behind as well
If it is possible to boot Hetzner from a BSD install image using "Linux rescue mode"^1 then it should also possible to run NetBSD entirely from memory using custom kernel
Every user is different but this is how I prefer to run UNIX-like OS for personal, recreational use; I find it more resilient
To enable a swap file in Linux, first create the swap file using a command like sudo dd if=/dev/zero of=/swapfile bs=1G count=1 for a 1GB file. Then, set it up with sudo mkswap /swapfile and activate it using sudo swapon /swapfile. To make it permanent, add /swapfile swap swap defaults 0 0 to your /etc/fstab file.
Works really well with no problems that I've seen. Really helps give a bit more of a buffer before applications get killed. Like others have said, with SSD the performance hit isn't too bad.
Get better VPS then. Openvz and other kernel paravirtualization have limits, go for Xen or KVM instead (Xen has paravirtualization as well, but I'm not sure how much it's actually used). Full virtualization (implemented by Xen and KVM) do not allow you to prevent swap from being used.
well once you "need" that swap, it will be writing pages across the network due to the storage being external to the physical server, so the latency is terrible
Latency of swap is always terrible in comparison to RAM. RAM vs disk is already something ~1000x right? I've never characterized EBS vs trad ssd, but I would be surprised if it's more than 10x.
I don't think using swap as "emergency RAM" makes a lot of sense in 2025. The arguments in favor of swap which I find convincing are about allowing the system to evict low use pages which otherwise would not be evictable.
They both offer virtualized guests under a hypervisor host. EC2 does have more offload specialization hardware but for the most part they are functionally equivalent, unless I'm missing something...
{kind=link}
{kind=link}
You can also enable zram to compress ram, so you can over-provision like the pros'. A lot of long-running software leaks memory that compresses pretty well.
Here is how I do it on my Hetzner bare-metal servers using Ansible: https://gist.github.com/fungiboletus/794a265cc186e79cd5eb2fe... It also works on VMs.